Lexical Analysis (Scanner) Phase of Compiler
2025, February 4
Lexical Analysis is the first phase of a compiler where raw source code is scanned and broken into meaningful units called tokens. It reads the program character by character, grouping them into lexemes (words) and assigning them token classifications. Think of it like breaking a paragraph into words and punctuation before analyzing its meaning.
✅ Key Role: Converts messy human-written code into structured components for easier processing by later compiler stages.
🔎 Example:
Consider the source code:
int age = 25;After lexical analysis, it becomes:
int → Keyword age → Identifier = → Operator 25 → Literal (Number) ; → Delimiter (End of Statement)Lexical analysis is necessary because computers cannot understand raw programming languages the way humans do.
Without Lexical Analysis, the compiler would struggle with:
🔎 Analogy:
Imagine a grocery list written with extra spaces, comments, and unnecessary characters:
# Buy these items
Milk 1ltr // Get fresh milk
Eggs 12 // Buy eggs with extra space
Lexical analysis cleans this up to just:
Milk 1ltr Eggs 12This helps in further processing the data efficiently.
Lexical analysis has three core components:
1️⃣ Lexeme: A sequence of characters that matches a pattern and forms a meaningful unit.
int, x, 422️⃣ Token: A classification assigned to a lexeme (like a label).
int (Keyword), x (Identifier), 42 (Number)3️⃣ Pattern: A rule or regular expression that defines how lexemes are recognized.
[a-zA-Z_][a-zA-Z0-9_]* (Pattern for valid variable names)🔎 Example Breakdown:
For this code:
float price = 99.99;| Lexeme | Token Type | Pattern |
|---|---|---|
| float | Keyword | int |
| price | Identifier | [a-zA-Z_][a-zA-Z0-9_]* |
| = | Operator | = |
| 99.99 | Number | [0-9]+(\.[0-9]+)? |
| ; | Delimiter | ; |
Lexical analysis works as an automated scanner that processes source code step-by-step.
📌 Step 1: Read Characters from Input
📌 Step 2: Recognize Lexemes and Match Patterns
📌 Step 3: Convert Lexemes into Tokens
📌 Step 4: Ignore Whitespaces and Comments
📌 Step 5: Handle Errors
🔎 Example Walkthrough (Processing int x = 10;)
| Step | Character Read | Recognized Lexeme | Token Output |
|---|---|---|---|
| 1 | i |
int |
Keyword |
| 2 | x |
x |
Identifier |
| 3 | = |
= |
Operator |
| 4 | 1 |
10 |
Number |
| 5 | ; |
; |
Delimiter |
Lexical analyzers automatically remove unnecessary characters before further processing.
✅ Whitespaces: Skipped unless inside string literals ("Hello World").
✅ Newlines: Ignored unless used for formatting (Python indentation).
✅ All Comments: Entirely removed before tokenization.
🔎 Example (Before & After Lexical Analysis)
// This is a comment
int a = 5; // Variable declaration
float b = 3.14;int a = 5;
float b = 3.14;This Python script simulates a basic lexer using regular expressions.
import re
# Define token patterns
token_patterns = [
(r'int|float|char', 'KEYWORD'),
(r'[a-zA-Z_][a-zA-Z0-9_]*', 'IDENTIFIER'),
(r'[0-9]+(\.[0-9]+)?', 'NUMBER'),
(r'=', 'OPERATOR'),
(r';', 'DELIMITER'),
(r'\s+', None) # Ignore whitespaces
]
def lexical_analyzer(code):
tokens = []
while code:
matched = False
for pattern, token_type in token_patterns:
regex = re.compile(pattern)
match = regex.match(code)
if match:
lexeme = match.group(0)
if token_type: # Ignore whitespaces
tokens.append((lexeme, token_type))
code = code[len(lexeme):] # Move to next lexeme
matched = True
break
if not matched:
raise ValueError(f"Unexpected character: {code[0]}")
return tokens
# Test lexer
code_sample = "int age = 25;"
tokens = lexical_analyzer(code_sample)
for lexeme, token in tokens:
print(f"{lexeme} -> {token}")✅ Output:
int -> KEYWORD
age -> IDENTIFIER
= -> OPERATOR
25 -> NUMBER
; -> DELIMITERTokenization is the process of breaking down a source program into a sequence of meaningful tokens. Each token is a fundamental unit of the language, representing a logical component like a keyword, identifier, or operator.
Each token consists of:
int, varName, 123).Tokens are classified into different categories:
Keywords are reserved words in a programming language that have special meanings and cannot be used as identifiers.
if, while, return, for, break.def, class, lambda, yield.function, var, let, const.Identifiers are user-defined names for variables, functions, and objects.
totalSum, myFunction, studentAge.Literals are fixed values assigned to variables, such as numbers, characters, and strings.
42, -5, 1000.3.14, 0.001, -2.718.'A', 'z', '5'."hello", "CompilerDesign".Operators perform computations and comparisons. They are categorized as:
+, -, *, /, %.==, !=, <, >, <=, >=.&& (AND), || (OR), ! (NOT).&, |, ^, ~, <<, >>.Special symbols are punctuation marks or delimiters that structure the code.
; (end of statement), , (comma separator).{} (block grouping), [] (arrays), () (function calls).The lexical analyzer (scanner) reads the source program character by character and groups them into tokens using:
For the input code:
int sum = 42 + 8;The lexer produces tokens:
| Lexeme | Token Name | Attribute |
|---|---|---|
| int | KEYWORD | int |
| sum | IDENTIFIER | Pointer to symbol table |
| = | OPERATOR | = |
| 42 | LITERAL | Integer |
| + | OPERATOR | + |
| 8 | LITERAL | Integer |
| ; | SPECIAL_SYMBOL | Statement Terminator |
= and == requires a two-character lookahead.\n, \t in strings.Lexical analyzers use Regular Expressions (RE) and Finite Automata (FA) to define and recognize token patterns in programming languages. These mathematical models efficiently describe how characters are grouped into meaningful tokens, ensuring correct identification of keywords, literals, identifiers, and operators.
A Regular Expression (RE) is a sequence of characters that defines a search pattern. It is a formal way to describe patterns in strings and is widely used in lexical analysis.
ab matches "ab".a|b matches "a" or "b".a* matches "", "a", "aa", "aaa", etc.a+ matches "a", "aa", "aaa", etc., but not "".a? matches "" or "a".[0-9] matches any digit.| Pattern | Description | Example Matches |
|---|---|---|
[a-zA-Z_][a-zA-Z0-9_]* |
Valid Identifiers | var_name, _temp, count1 |
[0-9]+ |
Integer Numbers | 42, 123, 9999 |
[0-9]*\.[0-9]+ |
Floating-point Numbers | 3.14, 0.5, .75 |
"([^"\\]|\\.)*" |
String Literals | "hello", "C Compiler" |
(if|while|for|return) |
Keywords | if, while, return |
\+\+|\-|\*|\/ |
Operators | ++, -, *, / |
Finite Automata are abstract machines used to implement lexical analyzers that recognize patterns defined by regular expressions. There are two main types:
A Deterministic Finite Automaton (DFA) is a state machine where each state has exactly one transition per input symbol.
stateDiagram
[*] --> S0
S0 --> S1 : [a-zA-Z_]
S1 --> S1 : [a-zA-Z0-9_]
S1 --> [*] : Accept (Identifier)
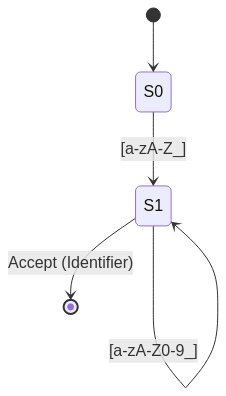
Explanation:
A Nondeterministic Finite Automaton (NFA) allows multiple transitions for the same input, meaning multiple states can be active at once.
graph TD
A[Start] -->|a-z, A-Z, _| B
B -->|a-z, A-Z, 0-9, _| B
B -->|ε| Accept
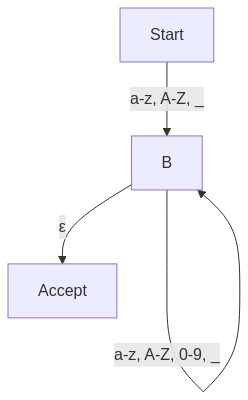
An NFA can be converted into an equivalent DFA using the Subset Construction Algorithm. This process removes ambiguity by constructing deterministic states from multiple NFA states.
| Feature | NFA | DFA |
|---|---|---|
| Number of transitions per state | Multiple allowed | One per input |
| Backtracking | Possible | Not required |
| Speed | Slower | Faster |
| Memory Usage | Lower | Higher |
| Conversion Complexity | Simple to construct | Requires subset construction |
Lexical errors occur when an input sequence of characters does not match any valid token pattern defined by the programming language's lexical rules. These errors are detected at the earliest stage of compilation (lexical analysis) and can prevent further processing.
Lexical errors arise due to:
Characters that are not part of the programming language's character set result in lexical errors.
# symbol is reserved for preprocessor directives but cannot appear in regular expressions.
int a = 10 # 5; // Error: Unexpected #
@ symbol is only allowed for annotations, not as an identifier character.
int @var = 5; // Error: Illegal character '@'
$ symbol is not valid in variable names.
$amount = 100 # Error: Unexpected '$' in identifier
Identifiers must follow specific naming conventions:
1var is invalid in most languages).my-variable is invalid in C but valid in JavaScript).
// Incorrect
int 1value = 10; // Error: Identifier cannot start with a digit
// Incorrect
int if = 5; // Error: 'if' is a reserved keyword
String literals must start and end with the correct delimiter, such as " or '. If the closing delimiter is missing, a lexical error occurs.
// Incorrect: Missing closing quote
printf("Hello world); // Error: Unterminated string literal
// Incorrect: Unmatched single quote
print('Welcome) // Error: Unclosed string literal
Numbers must follow proper formatting rules.
int num = 05; // Warning: Leading zero indicates an octal number
float x = 3..14; // Error: Unexpected '.'
Escape sequences are used inside string literals to represent special characters, but an incorrect escape sequence can cause a lexical error.
// Incorrect: \q is not a valid escape sequence
System.out.println("Hello \q World"); // Error
// Incorrect: \U starts a Unicode sequence but is incomplete
print("C:\Users\John") // Error: Incomplete Unicode escape sequence
Multi-line comments must be properly closed; otherwise, the lexer will reach the end of the file without finding the closure.
/* This is a comment
printf("Hello, World!"); // Error: Missing '*/'
The lexical analyzer (lexer) detects errors using Finite Automata and follows these strategies:
int 1number = 10;
System.out.println("Hello World);
The compiler output may be:
Error: Invalid identifier '1number' (line 1, column 5)
Error: Unterminated string literal (line 2, column 27)
| Lexical Error Type | Description | Example |
|---|---|---|
| Illegal Characters | Characters not in the language. | int x = 10 @ 5; (Error: '@') |
| Invalid Identifiers | Incorrect variable names. | int 1var = 5; (Error: Cannot start with a digit) |
| Unclosed Strings | Missing string delimiters. | print("Hello; (Error: Unterminated string) |
| Invalid Numbers | Incorrect numeric formats. | float x = 3..14; (Error: Double dots) |
| Unterminated Comments | Comment block not closed. | /* This is a comment (Error: Missing '*/') |
Lexical error recovery ensures that minor errors in the source code do not halt the compilation process completely. Instead of stopping execution on encountering an invalid token, modern compilers attempt to recover and continue processing the remaining code. This improves robustness and provides useful feedback to the programmer.
Lexical errors occur when a sequence of characters does not match any valid token pattern defined by the language. Common lexical errors include:
The simplest and most commonly used method where the lexer discards characters until a valid token is found.
int x = 5 @ 10;
In this case, `@` is an illegal character in C.
The lexer replaces an invalid token with a placeholder (e.g., `<TOKEN_ERROR>`) and continues scanning.
1var = 10In Python, identifiers cannot start with a digit.
For minor lexical mistakes, the lexer may suggest corrections based on the symbol table.
whil (x < 10) {
System.out.println(x);
}
The keyword `whil` is misspelled, but the lexer detects it as a probable `while`.
The lexer looks ahead to check if an error can be automatically corrected.
int x = 5.5.3;
This is invalid because `5.5.3` is not a valid floating-point number.
Modern compilers maintain error logs instead of immediately stopping execution on lexical errors.
In VS Code or IntelliJ, an incomplete statement like:
console.log("Hello;
Shows a warning: `Unclosed string literal` but allows further typing.
| Recovery Technique | Action Taken | Example |
|---|---|---|
| Panic Mode Recovery | Skip invalid tokens until a valid token is found. | `int x = 5 @ 10;` → Skips `@`. |
| Error Token Insertion | Replace invalid tokens with `<TOKEN_ERROR>`. | `1var = 10` → `<TOKEN_ERROR> = 10`. |
| Symbol Table Correction | Suggests possible corrections for mistyped keywords. | `whil (x < 10)` → Suggests `while`. |
| Lookahead Correction | Splits ambiguous tokens correctly. | `int x = 5.5.3;` → Splits into `5.5` and `.3`. |
| Logging & Reporting | Logs lexical errors without stopping execution. | VS Code highlights `console.log("Hello;` as an error. |
Lexical Analysis is widely used beyond compiler design. Many real-world systems and software applications depend on efficient tokenization, pattern recognition, and lexical scanning to process and understand textual data. Below are some key areas where lexical analysis plays a crucial role.
Lexical analysis is used in Integrated Development Environments (IDEs) and text editors to recognize different programming constructs and apply appropriate syntax highlighting.
Consider this Python snippet in an IDE:
def greet(name):
print("Hello, " + name + "!")
The lexer categorizes and highlights:
def (Keyword - Blue)greet (Function Name - White)name (Parameter - White)print (Built-in Function - Green)"Hello, " (String Literal - Yellow)Search engines such as Google and Bing use lexical analysis to extract meaningful words from user queries and match them against indexed web pages.
Consider a user searching for:
"Best places to visit in Paris during winter"
The lexer processes it as:
Lexical analyzers are essential in command-line interpreters like Bash, PowerShell, and Zsh to process user commands efficiently.
ls -l /home.Get-Process | Sort-Object CPU.Consider this Linux command:
grep "error" logfile.txt | sort | uniq -c
The lexer tokenizes the input as:
grep (Command - searches for a pattern in files)"error" (String Literal - search term)logfile.txt (Filename - argument)| (Pipe Operator - passes output to next command)sort (Command - sorts lines)uniq -c (Command - removes duplicates and counts occurrences)Lexical analysis, while crucial for efficient compilation, has several challenges that can cause incorrect tokenization, performance issues, or incompatibility with modern programming needs. Below are common pitfalls in lexical analysis and their debugging strategies.
Whitespace and comments do not contribute to program execution but must be handled carefully during lexical analysis to avoid inefficiencies.
//) and multi-line (/*...*/) comments should be skipped early.Consider this JavaScript code:
let x = 10; // This is a comment
console.log("Value: " + x);
If the lexer fails to remove comments properly, the comment may interfere with parsing. A debugging strategy involves:
Lexers must correctly distinguish between tokens that share prefixes (e.g., <= vs. < =).
= vs. ==).Consider this C++ expression:
if (x <= y)
if (x < = y)
The first line correctly recognizes <= as a single token, but the second line has ambiguity:
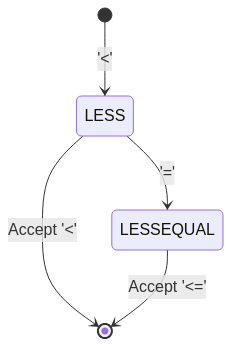
To resolve `<=` vs. `<=`, the DFA transitions should be structured as:
stateDiagram
[*] --> LESS : '<'
LESS --> LESSEQUAL : '='
LESS --> [*] : Accept '<'
LESSEQUAL --> [*] : Accept '<='
Modern compilers need to support Unicode characters, which introduces complexity in tokenization.
Valid variable names in Python:
变量 = 100 # Chinese variable name
π = 3.14 # Greek letter as identifier
[\p{L}_][\p{L}\p{N}_]*
This allows letters from any language in identifiers.
Optimizing lexical analysis is essential in industry applications where performance, memory efficiency, and speed are critical. Techniques such as DFA minimization and Just-In-Time (JIT) lexing help reduce overhead and improve real-time execution in modern compilers and interpreters.
Deterministic Finite Automaton (DFA) minimization is an optimization technique that reduces the number of states in a lexical analyzer, making token recognition faster and more efficient.
The Hopcroft's Algorithm is widely used for minimizing DFAs:
Consider a DFA that recognizes the keywords "if" and "int".
stateDiagram
[*] --> S0
S0 --> S1 : 'i'
S1 --> S2 : 'f'
S1 --> S3 : 'n'
S3 --> S4 : 't'
S2 --> [*] : Accept 'if'
S4 --> [*] : Accept 'int'
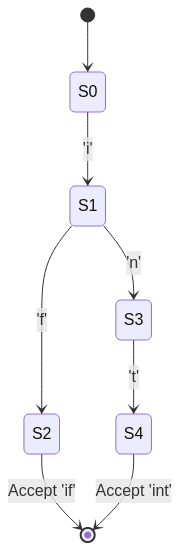
stateDiagram
[*] --> S0
S0 --> S1 : 'i'
S1 --> S2 : 'f' (if) / 'n' (int)
S2 --> [*] : Accept (if/int)

By merging states S3 and S4 into S2, we reduce the number of transitions, improving performance.
Just-In-Time (JIT) lexing is an on-demand tokenization technique where lexing occurs only when required, rather than preprocessing the entire source code in advance.
int main() {
int x = 10;
if (x > 5) {
printf("Hello");
}
}
The traditional lexer scans all tokens before parsing begins.
if condition():
execute()
JIT lexing only tokenizes the if-statement when `condition()` is called.