Parse Tree
2025, February 4
A parse tree is a hierarchical tree structure that represents how a string conforms to a given grammar. It is used in syntax analysis to check whether a given input string belongs to a language.
Given the following CFG for arithmetic expressions:
E → E + T | E - T | T
T → T * F | T / F | F
F → (E) | id
This grammar ensures that * and / have higher precedence than + and -, and that the operators + and - are left-associative.
id + id * idWe perform a step-by-step leftmost derivation, always replacing the leftmost nonterminal:
E
E
E using E → E + T
E ⇒ E + T
E (in E + T) using E → T
E + T ⇒ T + T
T using T → F
T + T ⇒ F + T
F with an identifier (F → id)
F + T ⇒ id + T
T (after the +) using T → T * F
id + T ⇒ id + T * F
T in T * F using T → F
id + T * F ⇒ id + F * F
F with id (F → id)
id + F * F ⇒ id + id * F ⇒ id + id * id
This leftmost derivation confirms that multiplication is performed before addition.
The parse tree visually captures the hierarchy of operations. Since multiplication has higher precedence than addition, the subtree for id * id is built first.
Start with the start symbol E:
E → E + TThis expansion introduces the addition operator:
E as E → T and then T → F with F → idThis gives the left operand:
T using T → T * FThis introduces the multiplication operator for the right operand:
T in the multiplication to T → F with F → idThis gives the left operand of multiplication:
F with idThis gives the right operand of multiplication:
The complete parse tree confirms that id + id * id is grouped as id + (id * id), reflecting correct operator precedence.
id + id * idIn a rightmost derivation we always replace the rightmost nonterminal first:
E
E
E using E → E + T
E ⇒ E + T
T) using T → T * F
E + T ⇒ E + T * F
F) with id
E + T * F ⇒ E + T * id
T * id (the T) using T → F
E + T * id ⇒ E + F * id
F) with id
E + F * id ⇒ E + id * id
E in E + id * id. Replace it using E → T
E + id * id ⇒ T + id * id
T using T → F
T + id * id ⇒ F + id * id
F with id
F + id * id ⇒ id + id * id
This rightmost derivation also leads to the expression id + id * id, with the multiplication carried out before addition.
The following parse tree illustrates the derivation when the rightmost nonterminal is replaced first:
E → E + TT using T → T * FF with idT_mult using T → F and then F → idE_left) by applying E → T, then T → F, and F → idThe complete parse tree again shows that the expression is parsed as id + (id * id), confirming the correct associativity and precedence.
The parsing steps demonstrated above correctly follow the CFG:
E → E + T | E - T | T
T → T * F | T / F | F
F → (E) | id
The fact that both the leftmost and rightmost derivations yield the same final parse tree indicates that the grammar is unambiguous. Here, although there are different derivation orders (leftmost versus rightmost), they both lead to the same unique tree structure for the expression id + (id * id).
The parse tree derived in section 2.2 and 2.4 confirms that id + id * id is grouped as id + (id * id) — ensuring that multiplication is evaluated before addition.
Explanation:
E represents the entire expression.+) has lower precedence than multiplication (*), the expression is parsed as id + (id * id).id * id is evaluated first, reflecting the operator precedence.A parse tree corresponds to both leftmost and rightmost derivations. These derivations determine the order in which nonterminals are expanded.
E → E + T
→ T + T
→ F + T
→ id + T
→ id + T * F
→ id + id * F
→ id + id * id
E → E + T
→ E + T * F
→ E + T * id
→ E + F * id
→ E + id * id
→ F + id * id
→ id + id * id
A grammar is ambiguous if there exists more than one valid parse tree for the same input string.
Consider this ambiguous grammar:
E → E + E | E * E | id
For the input string id + id * id, we get two possible parse trees:
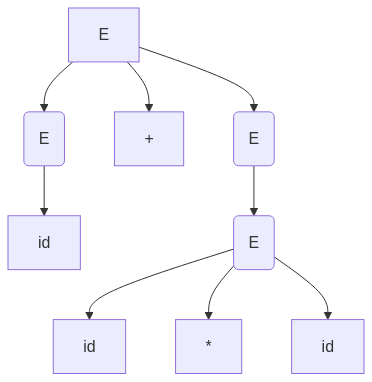
We begin with the input string: id + id * id
1. Start with E:
E → E + E (Choose rule for addition)
2. Expand the second E (right operand of +) as multiplication has higher precedence:
E → E + (E * E) (Choose rule for multiplication first)
3. Expand the operands:
E → id + (id * id)
4. Verify that multiplication is performed first due to its higher precedence.
Thus, the parse tree follows the correct operator precedence.
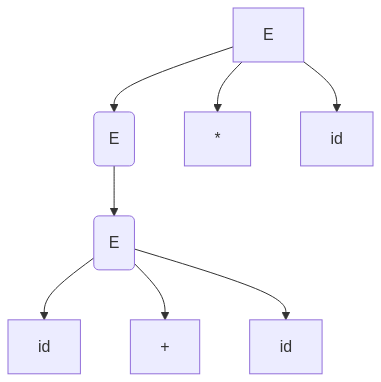
We begin with the same input string: id + id * id
1. Start with E:
E → E * E (Incorrect choice of multiplication first)
2. Expand the left operand first:
E → (E + E) * E (Addition is handled before multiplication, which is wrong)
3. Expand operands:
E → (id + id) * id
4. This results in incorrect evaluation since addition should not be performed before multiplication.
This parse tree incorrectly prioritizes addition over multiplication, violating standard arithmetic rules.
To remove this ambiguity, we modify the grammar to enforce operator precedence.
To enforce correct precedence, we modify the grammar:
E → E + T | T
T → T * F | F
F → id
Now, multiplication has higher precedence because:
T handles * before passing results to E.E only processes + after resolving all * operations.With this modification, we ensure that id + id * id is always parsed correctly as id + (id * id).
Parentheses change the evaluation order of expressions. Consider the following grammar:
E → (E) | E + E | E * E | id
For the input (id + id) * id, the parse tree looks like:
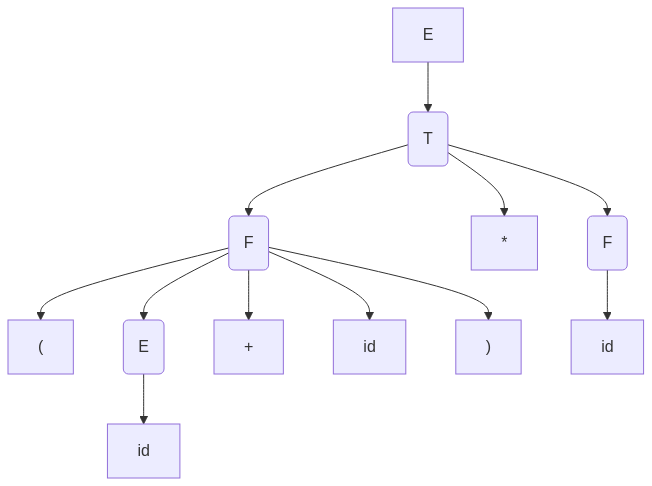
Explanation:
id + id is evaluated before multiplication.(id + id) is encapsulated inside F, ensuring correct precedence.We can use Python's nltk library to generate parse trees for a given grammar.
from nltk import CFG
from nltk.parse.chart import ChartParser
# Define a simple grammar
grammar = CFG.fromstring("""
S -> NP VP
NP -> 'John' | 'Mary' | 'dogs'
VP -> V NP | V
V -> 'barks' | 'sees'
""")
# Create a parser
parser = ChartParser(grammar)
# Parse the sentence
sentence = "John sees dogs".split()
for tree in parser.parse(sentence):
print(tree)
tree.pretty_print()
This code constructs a parse tree for the sentence "John sees dogs" based on the defined CFG.
Parse trees are essential for understanding the structure of expressions and programming languages. They provide a hierarchical view of syntax, guiding both parsing and code generation.