What is an Operating System?
An Operating System (OS) is a collection of software that manages computer hardware resources and provides common services for computer programs. The OS acts as an intermediary between users and the computer hardware. It enables user interaction with the hardware in an efficient and secure manner, managing tasks such as memory allocation, process scheduling, input/output operations, and file management.
Functions of an Operating System
- Process Management: Manages the execution of processes, including process scheduling, creation, termination, and synchronization.
- Memory Management: Allocates and manages the computer's primary memory, addressing, and swapping between main memory and disk during execution.
- Storage Management: Oversees data storage and retrieval on storage devices, managing file systems, directories, and permissions.
- Device Management: Controls hardware devices through their respective drivers, managing input/output operations and buffering.
- Security and Access Control: Protects system resources from unauthorized access while ensuring data integrity and privacy.
- User Interface: Provides interfaces for user interaction, such as command-line interfaces (CLI) or graphical user interfaces (GUI).
Different Types of Operating System
Operating systems can be classified based on their design and operational objectives. Each type serves specific applications, ranging from personal use to managing complex distributed systems.
Batch Systems
Batch operating systems are designed to process jobs without human interaction. Jobs are collected into batches of similar needs and executed sequentially. This approach maximizes resource utilization but may increase wait times for individual jobs.
Multi-programmed Systems
Multi-programmed systems enhance computational efficiency by running multiple programs simultaneously. This is achieved by keeping multiple programs in memory at the same time, utilizing CPU idle time caused by waiting for I/O operations to complete.
Time Sharing Systems
Time-sharing systems, or multitasking systems, extend the concept of multiprogramming by allocating a small time slice to each process in rotation. They offer interactive use of the system and rapid response times, allowing multiple users to share system resources simultaneously.
Personal Computer Systems
Designed for individual users, these systems focus on ease of use, responsiveness, and user interface design. They support a wide range of applications, from document processing to multimedia entertainment.
Parallel Systems
Parallel operating systems manage multiple processors to perform tasks concurrently, significantly increasing computing power and efficiency. These systems are crucial for high-performance computing tasks that require vast amounts of computational resources.
Distributed Systems
Distributed operating systems manage a collection of independent computers and make them appear to the user as a single coherent system. This setup is key for applications that require processing large datasets across multiple locations.
Real Time Systems
Real-time operating systems (RTOS) are designed to process data as it comes in, typically within a strict time constraint. They are used in systems where processing must occur within a defined time frame, such as embedded systems in automotive or medical devices.
Basic Concepts of Operating Systems
Operating Systems (OS) serve as the foundational software that manages computer hardware and software resources, offering common services for computer programs. This documentation aims to explain the intricate details of operating systems, focusing on their critical components, functionality, and the role they play in computer operation.
POST (Power-On Self Test)
The Power-On Self Test is the initial set of diagnostic tests performed by the computer's firmware, typically the BIOS (Basic Input/Output System), immediately after the computer is powered on. The purpose of POST is to ensure that the computer's hardware components are functioning correctly before loading the operating system. If the tests detect a failure in a critical component, the computer will not proceed to load the OS, and an error message will be displayed or beep codes will be emitted to indicate the problem.
Main Memory
Main Memory, also known as RAM (Random Access Memory), is the primary storage area that the CPU (Central Processing Unit) uses to store data and programs while they are being executed. RAM is volatile, meaning it loses its contents when the power is turned off. It plays a crucial role in determining the speed and performance of a computer, as it directly affects how quickly the CPU can access instructions and data needed for processing tasks.
Secondary Storage
Secondary Storage refers to non-volatile storage devices like HDDs (Hard Disk Drives), SSDs (Solid State Drives), and USB flash drives. Unlike main memory, secondary storage retains data even when the computer is turned off. It is used to permanently store data and programs that are not currently in use. The transfer of programs and data from secondary storage to main memory is a critical operation for program execution and data processing.
Virtual Memory
Virtual Memory is a memory management capability of an OS that uses hardware and software to allow a computer to compensate for physical memory shortages, by temporarily transferring data from random access memory (RAM) to disk storage. This process creates an illusion for users of a very large (virtual) memory space. Virtual memory allows for the execution of programs that may not completely fit in the main memory, by swapping pieces of data or program code in and out of the main memory as needed.
Transfer of Control from the Motherboard's BIOS to the Operating System (OS)
After the POST process concludes successfully, the control of the computer is transferred from the motherboard's BIOS to the Operating System. This transition is facilitated through the reading of the OS stored on the secondary storage device into the main memory. The BIOS identifies the bootable device, reads the boot sector, and executes the bootloader, which then loads the OS into memory, initiating the startup or boot process.
Definition and Role of an Operating System
An Operating System (OS) is system software that manages computer hardware, software resources, and provides common services for computer programs. The OS acts as an intermediary between users and the computer hardware, enabling efficient execution of user applications. It manages hardware resources such as the CPU, memory, and I/O devices, and ensures that different programs and users running on the computer do not interfere with each other.
Interface between Users and Computer Hardware
The Operating System provides an interface between the users and the computer hardware, facilitating the execution of user commands and the use of hardware resources. User interfaces can be graphical (GUIs), command-line (CLI), or touch-based, depending on the OS. This abstraction allows users to interact with the computer without needing to understand the complex details of hardware operations.
Layers of System Software
System software is organized in layers, enhancing the manageability and modularity of different components. The topmost layer consists of Application Programs, designed to fulfill end-user requirements. Utilities, providing system management and maintenance functions, form the middle layer. The Operating System constitutes the core layer, interfacing directly with computer hardware, managing resources, and providing services needed by other software layers.
Execution of a System/Machine with and Without an Operating System
With an OS, a computer can multitask, manage resources efficiently, and provide a user-friendly interface, facilitating the execution of complex tasks and applications. Without an OS, a computer would lack these capabilities, significantly limiting its functionality and requiring manual management of every hardware component for every task, a highly impractical scenario for modern computing needs.
Role of Utilities within an Operating System
Utilities are system software that perform system management, configuration, analysis, and maintenance tasks. They are essential for the optimal performance and operational efficiency of a computer system. Utilities help in managing files, disks, network settings, and perform system diagnostics and repair functions, thereby supporting the overall functionality of the operating system.
Programs in Secondary Memory and Their Transfer to Main Memory
Programs and data are stored in secondary memory due to its non-volatile nature. When a program is executed, the operating system transfers the program's executable code from secondary memory to main memory. This transfer is necessary because the CPU can only execute instructions that are in main memory. The efficient management of this transfer process is crucial for system performance and responsiveness.
Kernel
The kernel is the core component of an operating system, managing the system's resources and the communication between hardware and software components. It operates at the lowest level and performs functions such as memory management, process scheduling, and handling of input/output operations. The kernel enables applications to share hardware resources without interfering with each other, providing a stable and efficient computing environment.
Multitasking
Multitasking is the capability of an operating system to execute multiple processes simultaneously. This is achieved by managing how processes share the central processing unit (CPU), ensuring that each process gets a chance to execute within a specific time frame, thereby creating the illusion of concurrent execution. Multitasking increases the efficiency of CPU usage by organizing CPU time among multiple processes.
Basis of Time Division
Time division is a fundamental principle used in multitasking operating systems to allocate CPU time among multiple processes. The CPU time is divided into discrete intervals known as time slices or quantum. Each process is allowed to execute for a specified quantum before the next process is scheduled to run. This time-sharing mechanism ensures fair CPU allocation, enabling multiple processes to run seemingly in parallel on a single CPU.
Multiprocessor OS
Multiprocessor operating systems are designed to manage and utilize multiple CPUs within a single computer system. These systems provide enhanced performance and reliability by distributing the workload across several processors. Multiprocessor OSes are capable of executing multiple processes simultaneously across different CPUs, significantly improving the system's computational speed and efficiency.
Network and IP Addresses
An Internet Protocol (IP) address is a numerical label assigned to each device connected to a computer network that uses the Internet Protocol for communication. IP addresses serve two main functions: host or network interface identification and location addressing. Understanding IP addresses is crucial for networking, as they ensure that data reaches its correct destination across networks.
IP Address Structure
IP addresses are composed of two main parts: the network part and the host part. The network part identifies the specific network on which a device is located, while the host part identifies the specific device on that network. There are two versions of IP addresses commonly in use: IPv4 and IPv6. IPv4 addresses are 32 bits long, divided into four octets, and represented in decimal format. IPv6 addresses are 128 bits long, divided into eight 16-bit blocks, and represented in hexadecimal format to accommodate a vastly larger number of devices.
Classes
IP addresses are categorized into classes based on the first octet, which helps in identifying the network size. There are five classes in total, A through E, but for most practical purposes, Classes A, B, and C are most relevant.
- Class A: Supports 16 million hosts on each of 128 networks. It's identified by a first octet range of 1-126.
- Class B: Supports 65,000 hosts on each of 16,000 networks. Identified by a first octet range of 128-191.
- Class C: Supports 254 hosts on each of 2 million networks. Identified by a first octet range of 192-223.
Range
Each IP class has a specific range of addresses that it can accommodate, determined by the network's first octet. The range defines the possible network and host combinations.
| Public IP Range | Private IP Range | Subnet Mask | # of Networks | # of Hosts per Network | |
|---|---|---|---|---|---|
| Class A | 1.0.0.0 to 127.0.0.0 |
10.0.0.0 to 10.255.255.255 |
255.0.0.0 | 126 | 16,777,214 |
| Class B | 128.0.0.0 to 191.255.0.0 |
172.16.0.0 to 172.31.255.255 |
255.255.0.0 | 16,382 | 65,534 |
| Class C | 192.0.0.0 to 223.255.255.0 |
192.168.0.0 to 192.168.255.255 |
255.255.255.0 | 2,097,150 | 254 |
This structure allows for a hierarchical organization of networks, facilitating routing through the internet.
Subnetting
Subnetting is a method used to divide a single IP network into multiple smaller networks, enhancing the efficiency and security of network management. It involves borrowing bits from the host part of an IP address to create a subnet mask, which delineates the network and host portions of addresses within the subnet.
Special IP Addresses
There are special IP addresses reserved for specific purposes, such as private networks, multicast, and loopback testing.
- Private IP Addresses: Reserved for internal use within private networks, not routable on the internet. Includes ranges in Class A (10.0.0.0 to 10.255.255.255), Class B (172.16.0.0 to 172.31.255.255), and Class C (192.168.0.0 to 192.168.255.255).
- Loopback IP: 127.0.0.1 is used to test network software without physically sending packets out of the host.
- Multicast: Addresses in the range 224.0.0.0 to 239.255.255.255 are used for multicast groups.
IPv6
IPv6 addresses the limitation of IPv4 address exhaustion with a much larger address space. It introduces new features such as simplified header format, improved security, and better support for mobile devices and expanding networks.
Dynamic and Static IP Addresses
IP addresses can be static, permanently assigned to a device, or dynamic, temporarily assigned from a pool of addresses by a DHCP server. Static IP addresses are crucial for servers hosting websites, while dynamic IP addresses are cost-effective for general consumer devices.
IP Addressing and Routing
Routing is the process of forwarding IP packets from one network to another. Routers use routing tables to determine the best path for packet forwarding, based on the destination IP address.
Network Address Translation (NAT)
NAT is a method used to modify network address information in IP packet headers while in transit across a traffic routing device. It enables multiple devices on a private network to share a single public IP address, conserving global IP addresses and adding a layer of security.
Some common Differences in Operating Systems
Differences between IPv4 and IPv6
| Feature | IPv4 | IPv6 |
|---|---|---|
| Address Length | 32 bits | 128 bits |
| Address Format | Dotted decimal | Hexadecimal |
| Number of Addresses | Approximately 4.3 billion | Approximately 3.4 x 1038 |
| IPSec Support | Optional | Mandatory |
| Fragmentation | Performed by sending and forwarding routers | Performed by the sender only |
| Header Length | Variable, minimum 20 bytes | Fixed, 40 bytes |
| Checksum | Has header checksum | No header checksum |
| Address Configuration | Manual or via DHCP | Automatic, Stateless address autoconfiguration (SLAAC), or via DHCPv6 |
| NAT (Network Address Translation) | Widely used | Not required due to the large address space |
| Broadcast | Uses broadcast addresses | No broadcast addresses. Uses multicast instead |
| ARP (Address Resolution Protocol) | Uses ARP to map to MAC address | Uses NDP (Neighbor Discovery Protocol) instead |
Differences Between Primary, Secondary, and Virtual Memory
| Feature | Primary Memory | Secondary Memory | Virtual Memory |
|---|---|---|---|
| Type of Storage | Temporary storage (volatile) | Permanent storage (non-volatile) | A combination of RAM and disk space |
| Direct CPU Access | Yes | No | No, managed through OS |
| Speed | Fast | Slower than primary memory | Slower than primary memory |
| Cost per Bit | High | Low | Dependent on the underlying physical and secondary storage costs |
| Capacity | Limited | Large | Effectively large, limited by physical storage |
| Volatility | Volatile | Non-volatile | Depends on the backing storage |
| Purpose | To store data and instructions temporarily for quick access by CPU | To store data and programs permanently | To extend the apparent amount of physical memory |
| Technology Used | RAM, ROM | HDD, SSD, USB drives, CDs | Combination of RAM and disk space |
| Data Retention | Loses data on power off | Retains data without power | Depends on the physical storage component |
| Usage | Active processes and operating system components | Long-term storage and backup | Running large applications on systems with limited physical memory |
| Accessibility | Directly by the processor | Through I/O operations | Indirectly, managed by OS |
Role of the Dispatcher in the Process State Change
The dispatcher is a component of the operating system's scheduler responsible for the actual process of context switching from one process to another. Its primary role is to switch the CPU from the context of a currently running process to the context of the next process to run, based on the scheduling algorithm in use.
When the scheduler decides to execute a different process (during a state change from Ready to Running), the dispatcher performs the following actions:
- Saves the state of the currently running process (including its program counter, CPU registers, and other execution contexts) into its Process Control Block (PCB).
- Loads the state of the next process to run from its PCB into the CPU registers, updating the program counter to resume its execution.
- Transfers control to the selected process, effectively changing the process state to Running.
This mechanism is crucial for multitasking, allowing the OS to manage multiple processes efficiently, ensuring that each process gets a fair share of CPU time, and facilitating the seamless execution of numerous tasks.
Introduction to Process Creation and States
Process creation is a fundamental operation in operating systems, marking the inception of a new process. This involves allocating a unique Process ID (PID), allocating memory, and initializing process control structures. Processes transition through various states from creation to termination, influenced by scheduling decisions and system events. These states include New, Ready, Running, and Blocked/Wait, each reflecting the process's current status in the system.
Process vs. Processing
A process is an instance of a program in execution, characterized by its code, data, and state. It is an active entity with a program counter indicating the next instruction to execute and a set of associated resources. Processing, on the other hand, refers to the series of actions executed by the CPU to perform a task, such as executing instructions, performing calculations, and managing data transfers.
A process is a dynamic instance of an executable program, with its current state, data, and executing context, such as the values in its program counter, registers, and memory. It represents a single task or program in execution, encapsulated within its own virtual address space and system resources allocated by the operating system (OS). The OS manages processes through various states of execution, ensuring efficient CPU usage and multitasking capabilities.
Processing, conversely, refers to the action performed by a computer's CPU—the execution of instructions that make up a program or process. Processing involves arithmetic calculations, logical operations, data transfer, and control flow management, executing the sequence of instructions that constitute the software being run. While a process is an entity, processing is an activity, signifying the work the CPU undertakes to perform tasks and execute programs.
Definition of a Process
A process is a program in execution, encompassing the program code, its current activities, and the resources assigned to it by the operating system. Each process is uniquely identified and managed by the OS, facilitating multitasking by allowing multiple processes to share CPU and system resources efficiently.
Process Scheduling
Process scheduling is a fundamental operating system function that manages the execution of processes by determining which process runs at any given time. It optimizes the use of the CPU by allocating resources among various processes, ensuring efficient execution, responsiveness, and system throughput. The scheduling strategy may vary depending on the specific requirements of the operating system and the tasks it supports.
Attributes of Processes
Each process in an operating system is characterized by a set of attributes, including:
- Process ID (PID): A unique identifier assigned by the operating system to distinguish each process.
- Process State: The current state of the process (e.g., New, Ready, Running).
- Process Priority: Determines the order in which processes are scheduled for execution, affecting the process's access to CPU time.
- Program Counter (PC): Holds the address of the next instruction to be executed for this process.
- Memory Pointers: References to the process's code, data, and stack in memory.
- CPU Registers: The current working variables of the process.
- General Purpose Registers: Store temporary data and are used during instruction execution.
- Accounting Information: Usage statistics like CPU time consumed.
These attributes are managed through the Process Control Block (PCB), which serves as the kernel's primary data structure for process management.
Program Counter (PC)
The Program Counter (PC) is a component of the CPU that stores the memory address of the next instruction to be executed by a process. After each instruction is executed, the PC is updated to point to the next instruction. The PC ensures the sequential execution of a program's instructions, guiding the CPU through a process's code.
Process Control Block (PCB)
The Process Control Block is a data structure maintained by the operating system for every process. The PCB contains essential information about the process, including its process ID, process state, program counter, CPU registers, scheduling information, memory management information, and accounting information. The PCB is crucial for the OS to manage all processes efficiently.
Process State Diagram
The process state diagram visually represents the transitions between the various states of a process throughout its lifecycle. It illustrates how a process moves from the New state to the Ready state, then to Running, possibly cycling through Waiting (if it needs to wait for resources or events), and finally moving to the Terminated state upon completion.
The diagram is crucial for understanding how the OS manages processes, scheduling them for execution, and handling them when they are no longer active.
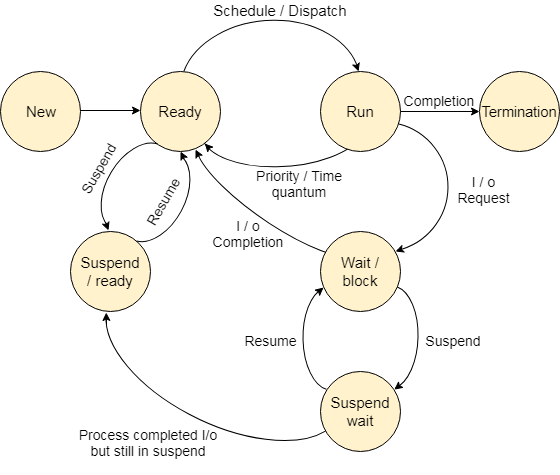
- A circular or looped diagram can illustrate the lifecycle of a process, showing arrows from New to Ready (initiated by the long-term scheduler), from Ready to Running (by the short-term scheduler), from Running to Waiting/Blocked (when a process waits for I/O or resources), and from Waiting/Blocked back to Ready (once the wait is over).
- Additional arrows show processes being terminated from the Running state or being swapped in and out of memory by the medium-term scheduler.
Process States and Lifecycle
The lifecycle of a process in an operating system is marked by its transition through several states from creation to termination. These states are:
- New: The process is being created. This is the initial phase where the OS allocates memory and other resources.
- Ready: The process has all necessary resources and is waiting to be assigned to the CPU for execution.
- Running: The process is currently being executed on the CPU.
- Waiting: The process is not executing because it is waiting for some event or resource to become available.
- Terminated: The process has finished execution and is waiting to be removed from the system by the OS, releasing all allocated resources.
These states ensure that the OS efficiently manages CPU time among multiple processes, balancing system load and responding to user and system tasks dynamically.
Process State Transitions
Processes undergo several state transitions in their lifecycle, managed by the operating system schedulers:
- From New to Ready: Once the long-term scheduler decides to admit a new process into the system, it transitions from the New state to the Ready state, where it waits for the short-term scheduler to allocate the CPU.
- From Ready to Running: The short-term scheduler selects a process from the Ready queue and allocates the CPU to it, changing its state to Running.
- From Running to Waiting/Blocked: If the process requires an I/O operation or needs to wait for a resource, it transitions from Running to the Waiting/Blocked state, releasing the CPU.
- From Waiting/Blocked to Ready: Once the I/O operation is complete or the awaited resource becomes available, the process transitions back to the Ready state, waiting for the CPU to be allocated again.
These transitions are critical for multitasking and efficient CPU utilization, ensuring that processes do not waste valuable CPU time waiting for resources or I/O operations to complete.
Dispatching
Dispatching is the process by which the CPU scheduler selects a process from the ready queue and assigns the CPU to it. The dispatcher is responsible for the context switch, switching the processor from executing one process to executing another. It involves loading the context (state and data) of the selected process into the CPU registers and updating various management structures within the operating system. Dispatching is a crucial step in process scheduling, enabling multitasking and efficient use of CPU resources.
Scheduler Types
The operating system employs different types of schedulers to manage processes through their lifecycle, each with a specific role:
- Long-term Scheduler (or Job Scheduler): Decides which jobs or processes are admitted to the system for processing. It controls the degree of multiprogramming, i.e., the number of processes in memory. The long-term scheduler determines when to move new processes to the ready state.
- Short-term Scheduler (or CPU Scheduler): Selects from among the processes that are ready to execute and allocates the CPU to one of them. It's invoked frequently and must be fast, as it affects the system's responsiveness and performance directly.
- Medium-term Scheduler (or Swapper): Temporarily removes processes from active contention for the CPU to control the level of multiprogramming. This scheduler may swap out processes to disk, moving them from the waiting state back to the ready state, or vice versa, to balance the mix of CPU-bound and I/O-bound processes.
Long Term Scheduler (LTS)
The Long Term Scheduler, or Job Scheduler, controls the admission of processes into the system. It decides which processes are introduced into the pool of executable tasks based on policies that might consider the mix of CPU-bound and I/O-bound processes, the priority of tasks, or other criteria. The LTS plays a crucial role in determining the degree of multiprogramming, directly impacting system performance and resource utilization.
Short Term Scheduler (STS)
The Short Term Scheduler, or CPU Scheduler, selects from among the processes in the Ready state and allocates the CPU to one of them. This scheduler operates more frequently than the LTS, making rapid decisions to ensure the efficient use of the CPU. The STS can employ various scheduling algorithms to determine the execution order of processes.
Priority-based Process Replacement
In systems employing priority scheduling, processes may be preempted or replaced based on priority. A running process with a lower priority might be interrupted and moved to the Ready or Waiting state if a higher priority process becomes ready to execute. This mechanism ensures that critical tasks receive the CPU time they require, optimizing the system's responsiveness to priority changes.
Scheduler Queues and Their Functions
Processes in an operating system are placed in various queues, each managed by different schedulers and serving unique functions:
- Job Queue: Holds all the processes in the system. The LTS selects processes from this queue to load into the ready queue.
- Ready Queue: Contains all processes that are in memory and ready to execute but are waiting for CPU time. The STS selects processes from this queue for execution.
- Waiting Queue: Contains processes that are waiting for an event or I/O operation to complete. Once the waiting condition is met, processes are moved back to the ready queue.
These queues are essential for managing process states and transitions, facilitating efficient scheduling and execution.
Time Slice Allocation for Processes
Time slice allocation, also known as quantum, is a critical aspect of the Round Robin (RR) scheduling algorithm used by the STS. A time slice is a fixed time period allocated to each process in the ready queue before the CPU is switched to another process. The allocation of time slices ensures that each process gets a fair share of CPU time, preventing any single process from monopolizing the CPU. The length of the time slice can significantly affect system performance, with shorter slices leading to higher context switch overhead but more responsive system behavior, and longer slices reducing context switch overhead but potentially leading to less responsive behavior for interactive processes.
Context Switching
Context switching is the process of saving the state of a currently running process and restoring the state of another process to resume its execution. This operation is fundamental to multitasking, allowing the CPU to switch rapidly between processes and utilize time efficiently. Context switching involves overhead, as the system must save and load register contents, stack pointers, and program counters, but it is essential for achieving concurrent execution of multiple processes.
Scheduling Algorithms
Scheduling algorithms are strategies employed by the STS to determine which process in the Ready queue should be allocated the CPU next. Common algorithms include:
- First-Come, First-Served (FCFS): Processes are scheduled according to their arrival time.
- Shortest Job First (SJF): Processes with the shortest estimated run time are scheduled first.
- Round Robin (RR): Processes are scheduled in a circular order, using time slices called quanta.
- Priority Scheduling: Processes are scheduled based on priority, with higher priority processes being executed first.
Each algorithm has its advantages and trade-offs, affecting factors like throughput, turnaround time, and responsiveness We will learn about them in detail in next articles.
Different Types of Time Related to Processes
In process scheduling, several time metrics are crucial for analyzing system performance and the efficiency of scheduling algorithms. Understanding these metrics is essential for optimizing process execution and system throughput.
Arrival Time
Arrival Time refers to the time at which a process enters the system or becomes ready for execution. It's the point when a process is added to the Ready Queue.
Completion Time
Completion Time is the moment a process completes its execution and exits the system. It marks the end of the process's lifecycle.
Burst Time
Burst Time, also known as Execution Time, is the total time a process requires the CPU for its execution. It doesn't include waiting or I/O operations time.
Turnaround Time
Turnaround Time is the total time taken for a process from its arrival to its completion. It includes all bursts of execution, waiting time, and performing I/O operations. Mathematically, it's calculated as:
$$\text{Turnaround Time} = \text{Completion Time} - \text{Arrival Time}$$
Waiting Time
Waiting Time is the total time a process spends in the Ready Queue waiting for CPU time. It's calculated by subtracting the total burst time of the process from its turnaround time.
$$\text{Waiting Time} = \text{Turnaround Time} - \text{Total Burst Time}$$
Response Time
Response Time is the interval from the arrival time of a process to the time of the first response by the CPU. Essentially, it's the duration before a process starts execution. For non-preemptive systems, response time and waiting time are identical.
Calculations and Examples Related to Process Times
Let's consider a simple system with three processes to demonstrate how these times are calculated:
- Process 1: Arrival Time = 0, Burst Time = 5
- Process 2: Arrival Time = 2, Burst Time = 3
- Process 3: Arrival Time = 4, Burst Time = 1
Assuming a First-Come, First-Served (FCFS) scheduling algorithm:
- Completion Time for Process 1 is at time 5, Process 2 is at time 8 (5 + 3), and Process 3 is at time 9 (8 + 1).
- Turnaround Time for Process 1 is \(5 - 0 = 5\), for Process 2 is \(8 - 2 = 6\), and for Process 3 is \(9 - 4 = 5\).
- Waiting Time for Process 1 is \(5 - 5 = 0\), for Process 2 is \(6 - 3 = 3\), and for Process 3 is \(5 - 1 = 4\).
- Response Time in a FCFS system is identical to the Waiting Time for each process.