Syntax Analysis (Parser) Phase of Compiler
2025, February 5
Syntax Analysis, also known as parsing, is the second phase of the compilation process. It takes the sequence of tokens generated by the lexical analyzer and organizes them into a structured format, typically represented as a parse tree or syntax tree.
The main goal of syntax analysis is to verify whether the sequence of tokens follows the grammatical rules of the programming language.
Key Function: Ensures that the program structure is valid before proceeding to further compilation phases.
Consider the following C statement:
int x = 10 + 5 * 2;After lexical analysis, it is converted into a sequence of tokens:
[int, identifier(x), =, number(10), +, number(5), *, number(2), ;]Syntax analysis checks whether this sequence conforms to the grammar of the language and generates a parse tree.
Syntax analysis plays a crucial role in ensuring that a program adheres to the correct structure defined by a language.
Consider the following Java code:
int a = 5 + ;This will result in a syntax error because a valid expression must follow the `+` operator.
However, the following code:
int a = 5 / 0;Has correct syntax but results in a semantic error (division by zero).
Syntax analysis consists of several key components that work together to process and validate the structure of a program.
A context-free grammar (CFG) defines the rules for valid syntax in a programming language. It consists of:
CFG provides a structured approach to define the syntax of a language.
A parse tree is a tree representation of how an input follows the grammar rules.
Example for expression 3 + 4 * 5:
.
+
/ \
3 *
/ \
4 5
Parsers analyze tokens using different techniques:
Syntax analysis also involves detecting and handling errors.
Syntax analysis follows a structured approach to process tokens and check for valid syntax.
The parser takes a sequence of tokens from the lexical analyzer.
The parser attempts to match token sequences to production rules in the grammar.
If the tokens match a valid rule, a parse tree is generated.
If an invalid sequence is encountered, the parser reports a syntax error and attempts to recover.
Context-Free Grammar (CFG) is a formal system used to describe the syntax of programming languages. It defines how valid statements and expressions are formed by breaking them into smaller components using a set of production rules.
A CFG is formally defined as a 4-tuple: G = (N, T, P, S), where:
if, +, identifier).Expression, Statement).Program), from which parsing begins.Consider a simple arithmetic expression grammar:
E → E + T | E - T | T
T → T * F | T / F | F
F → ( E ) | id
E (Expression): Represents an entire arithmetic expression.T (Term): Represents multiplication/division operations.F (Factor): Represents atomic values (identifiers or parenthesized expressions).The following derivation shows how CFG expands an arithmetic expression.
3 + 4 * (5 - 2)
E → E + T
→ T + T
→ F + T
→ 3 + T
→ 3 + T * F
→ 3 + F * F
→ 3 + 4 * (E)
→ 3 + 4 * (E - T)
→ 3 + 4 * (F - T)
→ 3 + 4 * (5 - 2)
graph TD;
E --> E1["+"] --> T1["3"];
E1 --> T2["T"];
T2 --> T3["T"] --> F2["4"];
T3 --> Op["*"];
T3 --> F3["( E )"];
F3 --> E2["E"];
E2 --> E3["E - T"];
E3 --> F4["5"];
E3 --> Op2["-"];
E3 --> T4["2"];
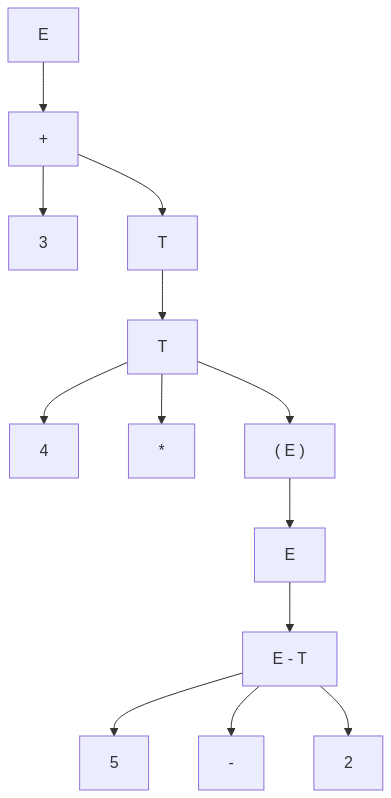
(5 - 2) inside 4 * (5 - 2)).An ambiguous grammar can generate multiple valid parse trees. To resolve this, we modify the rules to enforce precedence and associativity.
E → E + E | E * E | id
This grammar allows multiple ways to derive 2 + 3 * 4, causing ambiguity.
To enforce correct precedence, we rewrite it as:
E → E + T | T
T → T * F | F
F → id
Now, 3 + 4 * 5 is always parsed as 3 + (4 * 5).
Parsing techniques are methods used by the syntax analyzer to verify whether a sequence of tokens follows the syntactic rules of a programming language. They determine how the compiler interprets source code and builds syntax trees.
Parsing techniques are categorized into two major types:
LL(1) parsing is a predictive parsing technique that scans input from Left to right (L), produces Leftmost derivations (L), and uses 1-token lookahead (1).
E → T E'
E' → + T E' | ε
T → F T'
T' → * F T' | ε
F → ( E ) | id
| Non-Terminal | Token: id | Token: ( | Token: + | Token: * | Token: ) | Token: $ |
|---|---|---|---|---|---|---|
| E | T E' | T E' | ||||
| E' | + T E' | ε | ε | |||
| T | F T' | F T' | ||||
| T' | ε | * F T' | ε | ε | ||
| F | id | ( E ) |
graph TD;
Start["E"]
Start --> T["T"]
T --> F["F"]
F --> id["id"]
Start --> E'["\+ T E'"]
E' --> Plus["\+"]
E' --> T2["T"]
T2 --> F2["F"]
F2 --> id2["id"]
T2 --> T'["\* F T'"]
T' --> Mul["\*"]
T' --> F3["id"]
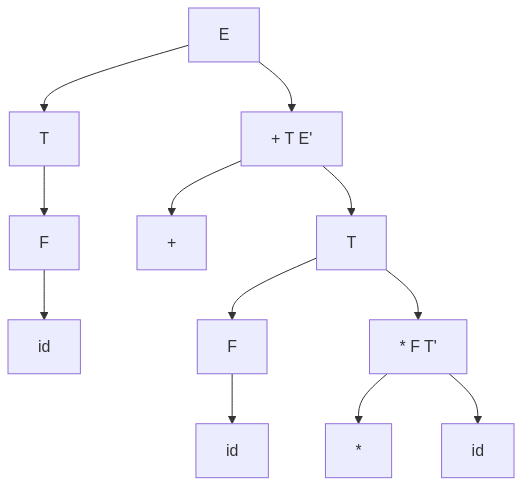
LR(1) parsing is a shift-reduce parsing technique that scans input from Left to right (L), produces Rightmost derivations (R), and uses 1-token lookahead (1).
E → E + T | T
T → T * F | F
F → ( E ) | id
For input: id + id * id
| Stack | Input | Action |
|---|---|---|
| [] | id + id * id | Shift |
| [id] | + id * id | Reduce F → id |
| [F] | + id * id | Reduce T → F |
| [T] | + id * id | Shift |
| [T +] | id * id | Shift |
| [T + id] | * id | Reduce F → id |
| [T + F] | * id | Reduce T → F |
| [T + T] | * id | Shift |
| [T + T *] | id | Shift |
| [T + T * id] | Reduce F → id | |
| [T + T * F] | Reduce T → T * F | |
| [T + T] | Reduce E → E + T |
Recursive descent parsing is a top-down technique where each non-terminal is implemented as a recursive function.
Grammar:
E → T E'
E' → + T E' | ε
T → F
F → id | ( E )
Recursive descent implementation in Python:
def E():
T()
E_prime()
def E_prime():
if lookahead == '+':
match('+')
T()
E_prime()
def T():
F()
def F():
if lookahead == 'id':
match('id')
elif lookahead == '(':
match('(')
E()
match(')')
An Abstract Syntax Tree (AST) is a hierarchical, tree-like representation of a program’s structure. Unlike a parse tree, which strictly follows grammar rules, an AST provides a condensed and meaningful representation that is closer to execution logic.
| Feature | Parse Tree | AST |
|---|---|---|
| Represents | Entire grammar structure | Essential syntax for computation |
| Size | Larger (includes all grammar rules) | Smaller (removes unnecessary nodes) |
| Usability | Not suitable for code generation | Used in semantic analysis & optimization |
| Example Usage | Syntax checking | Code optimization, execution |
graph TD;
E["E"]
E --> E1["\+"] --> T1["T"]
E1 --> plus["\+"]
E1 --> T2["T"]
T1 --> F1["F"]
F1 --> a["a"]
T2 --> T3["T"] --> F2["F"]
F2 --> b["b"]
T3 --> mult["\*"]
T3 --> F3["F"]
F3 --> c["c"]
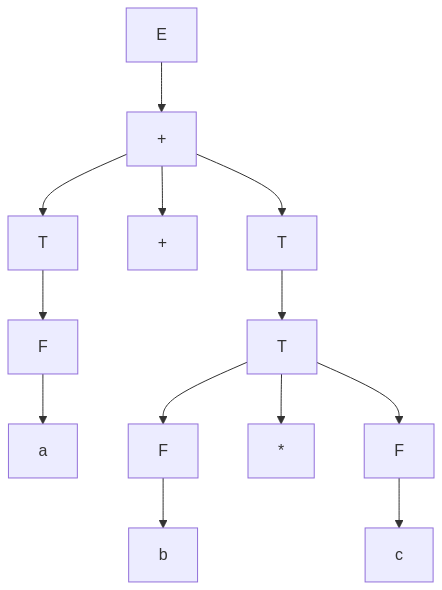
graph TD;
plus["\+"] --> a;
plus["\+"] --> mult["*"];
mult["\*"] --> b;
mult["\*"] --> c;
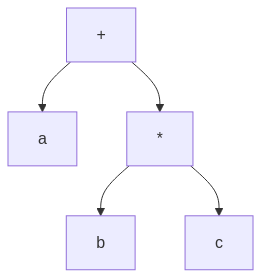
Observations:
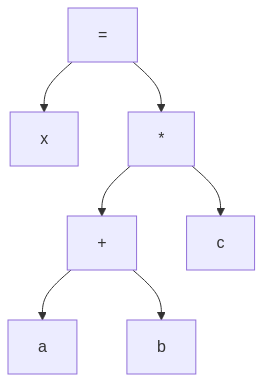
ASTs are constructed using postfix traversal of the parse tree:
graph TD;
assign["\="] --> x;
assign["\="] --> mult["\*"];
mult["\*"] --> plus["\+"];
plus["\+"] --> a;
plus["\+"] --> b;
mult["\*"] --> c;
Modern compilers apply optimization techniques on ASTs before generating machine code.
Computes constant expressions at compile time.
// Original code
x = 5 + 3 * 2;
// Optimized AST
x = 5 + 6;
x = 11;
Removes unreachable or redundant code.
if (false) { x = 10; } // Eliminated at AST stage
Reuses computed expressions to save execution time.
y = (a + b) * c;
z = (a + b) * d;
After AST optimization:
temp = a + b;
y = temp * c;
z = temp * d;
Once the AST is built and optimized, the compiler translates it into low-level code (assembly, bytecode, or machine code).
// Expression: a + b * c
mov R1, b
mul R1, c
add R1, a
Consider the following Context-Free Grammar (CFG) for arithmetic expressions:
We define the following CFG:
E → E + E | E * E | ( E ) | id
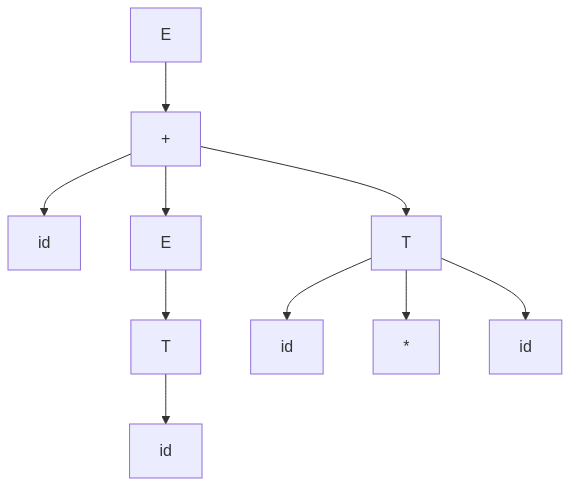
For the input string:
id + id * id
The following parse trees illustrate different ways to derive id + id * id.
graph TD;
E --> E1["\+"] --> T1["id"];
E1 --> E2["E"];
E2 --> T2["T"];
T2 --> F["id"];
E1 --> T3["T"];
T3 --> F2["id"];
T3 --> Op["\*"];
T3 --> F3["id"];
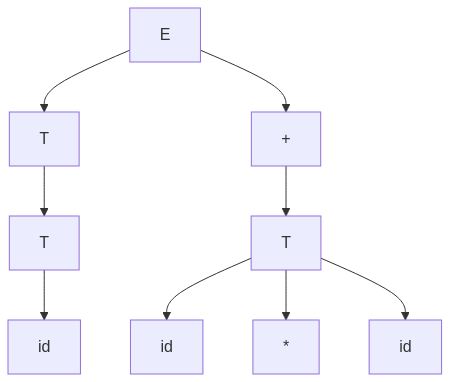
graph TD;
E --> E1["T"];
E1 --> T1["T"];
T1 --> F1["id"];
E --> Op["\+"] --> T2["T"];
T2 --> F2["id"];
T2 --> Op2["\*"];
T2 --> F3["id"];
A left-most derivation expands the leftmost non-terminal first at each step.
E → E + E
→ id + E
→ id + E * E
→ id + id * E
→ id + id * id
Each step replaces the leftmost non-terminal with one of its production rules.
A right-most derivation expands the rightmost non-terminal first.
E → E + E
→ E + E * E
→ E + E * id
→ E + id * id
→ id + id * id
Each step replaces the rightmost non-terminal with one of its production rules.
Click to read the concept in detail
id + (id * id)id + (id * id)A grammar is ambiguous if the same input has multiple valid parse trees.
Since multiple valid trees exist, the grammar is ambiguous.
To resolve ambiguity, we modify the grammar to define precedence and associativity explicitly.
E → E + T | T
T → T * F | F
F → ( E ) | id
graph TD;
E["\+"] --> T1["T"];
E["\+"] --> T2["T"];
T1 --> F1["id"];
T2 --> Op["\*"];
T2 --> F2["id"];
T2 --> F3["id"];
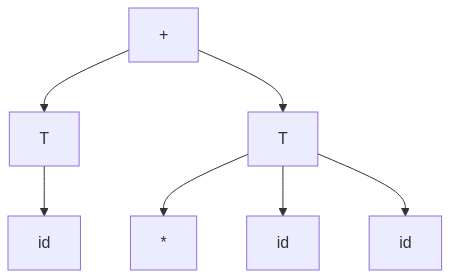
AST (Abstract Syntax Tree) simplifies the parse tree by removing redundant grammar rules.
graph TD;
plus["\+"] --> id;
plus["\+"] --> mult["\*"];
mult["\*"] --> id;
mult["\*"] --> id;
Syntax analysis plays a crucial role in real-world applications beyond compiler design. It is widely used in integrated development environments (IDEs), database systems, and various tools that require structured text processing.
Modern IDEs rely on parsers to validate source code, detect syntax errors, and provide real-time assistance through auto-completion and error highlighting.
Consider this Python code with a syntax error:
def greet(name)
print("Hello, " + name + "!")
The parser will generate an error:
SyntaxError: expected ':'
The missing colon (:) is detected by the parser before execution.
When typing:
System.out.pri
The parser suggests:
System.out.print
System.out.println
Databases use syntax analysis to parse SQL queries and verify their correctness before execution.
Consider the following SQL query:
SELECT name age FROM users WHERE id = 10;
The parser detects a missing comma:
SyntaxError: Expected ',' between column names
After parsing, SQL databases optimize queries:
Syntax analysis is a crucial phase in the compilation process, but it comes with several challenges. Ambiguous grammars, errors in recursive descent parsing, and recovering from syntax errors require careful handling to ensure accurate and efficient parsing.
Ambiguous grammars allow multiple parse trees for a single input, leading to uncertainty in parsing. One common example is the dangling else problem.
Consider the following ambiguous grammar for conditional statements:
Stmt → if Expr then Stmt | if Expr then Stmt else Stmt | other
Given this input:
if (x > 0)
if (y > 0)
print("Both positive");
else
print("x is negative");
The ambiguity arises because the else statement could belong to either the inner or outer if.
{} to remove ambiguity.
Stmt → MatchedStmt | UnmatchedStmt
MatchedStmt → if Expr then MatchedStmt else MatchedStmt | other
UnmatchedStmt → if Expr then Stmt | if Expr then MatchedStmt else UnmatchedStmt
Recursive descent parsers are easy to implement but can face infinite recursion, backtracking inefficiencies, and left recursion issues.
Consider the left-recursive grammar:
E → E + T | T
T → int | (E)
The recursive descent parser for E would never terminate, as it always calls itself first.
Rewrite the grammar to remove left recursion:
E → T E'
E' → + T E' | ε
T → int | (E)
Now, parsing avoids infinite recursion.
A syntax error occurs when the source code does not follow the grammar rules. A good parser should handle errors gracefully without stopping compilation.
Immediately discards tokens until a known synchronizing token is found (e.g., semicolon, closing brace).
Attempts to replace incorrect tokens with plausible alternatives.
int x 5; is found, replace 5 with = 5.Adds specific rules to handle common errors.
else appears without an if, issue a warning.Uses sophisticated algorithms to suggest corrections.
Consider the erroneous code:
int main() {
printf("Hello World")
}
The parser detects:
SyntaxError: Expected ';' after printf statement.
Modern compilers employ advanced optimization techniques in syntax analysis to ensure efficient parsing, reduced ambiguity, and improved performance. The following methods—associativity, operator precedence parsing, and lookahead parsing—are widely used in industry-grade parsers.
Associativity determines how operators of the same precedence are grouped in an expression. This rule prevents ambiguity and ensures consistent evaluation.
These operators evaluate from left to right.
a - b - c // Evaluated as (a - b) - c
a / b / c // Evaluated as (a / b) / c
These operators evaluate from right to left.
a = b = c // Evaluated as a = (b = c)
x ^ y ^ z // In some languages, exponentiation is right-associative
These operators cannot be chained together.
a < b < c // Syntax error in some languages
Associativity rules are enforced in parsing tables and Abstract Syntax Trees (ASTs).
Operator precedence parsing ensures correct evaluation order for mathematical and logical expressions.
// Without precedence, this is ambiguous:
x = 5 + 3 * 2 // Should be x = 5 + (3 * 2), not (5 + 3) * 2
Compilers use a precedence table to resolve expression parsing:
| Operator | Associativity | Precedence |
|---|---|---|
* / % |
Left | 3 |
+ - |
Left | 2 |
= |
Right | 1 |
Operator precedence parsing uses shift-reduce parsing, where:
graph TD;
Start --> Num1[5]
Num1 --> Op1[+]
Op1 --> Num2[3]
Num2 --> Op2[*]
Op2 --> Num3[2]
Op2 --> Reduce[Apply * before +]
Lookahead parsing improves efficiency by predicting which rule to apply next without backtracking.
Consider the grammar:
Stmt → if Expr then Stmt | while Expr do Stmt | other
With lookahead parsing:
if Expr then Stmt.while Expr do Stmt.For the input:
if (x > 0) then print("Positive");
The parser makes decisions without backtracking:
graph TD;
Start --> Lookahead["Lookahead Token: if"]
Lookahead --> MatchIf["Match: if"]
MatchIf --> Expr["Parse Expression (x > 0)"]
Expr --> MatchThen["Match: then"]
MatchThen --> PrintStmt["Parse Print Statement"]
